The following essay was originally written as a contribution intended for the Routledge Handbook of Architecture, Urban Space and Politics. I proposed and drafted it in early 2020, and then submitted it for peer review. I returned to work on the final edit in July 2021, having not thought about the work for some six months, and noticed that a new paper with a very similar thesis (and deeper research regarding the neoreactionary intellectual genealogies) had been published in April 2021 about Urbit. Not feeling equipped to update the paper to adequately reflect and build upon that work, having moved onto other research topics, I withdrew my chapter from the publication.
I make it available here as a ’preprint’ in the spirit of sharing unfinished academic work I am particularly grateful to Nikolina Bobic and Farzaneh Haghighi for their close reading of the work in its draft stages, and their understanding regarding the non-publication at the time. Thank you also to Chiara Ficarelli, Francis Tseng, all those in Brown University’s STS reading group for their varied contributions in form and kind. Thank you also to the reviewer two of the first draft of this piece as it was originally submitted to the handbook, who put much needed pressure on the more extensive use of Lefebvre’s ideas that existed in early drafts. All editorial and formatting mistakes are mine, as the piece is slightly restructured in comparison to what was originally submitted for the handbook.
(If this website isn't rendering nicely or you want to read this offline, see the PDF version.)
The set is small town America, a fictional place nested in real space: Hawkins, Indiana. The animal print clothing, Kate-Bush-heavy soundtrack and over-militarized technological anxiety attest to that space’s imagined time: Reagan’s 80s, as the Cold War runs out of breath.
Russia is not the only enemy, however. In fact, it is small change in the grand scheme of a larger threat. Creatures and consciousnesses from the ’Upside Down’, a dimension that mirrors the world in spatial equivalence, creep in and render life precarious in all its forms through fissures known as gates. These faceless monstrosities are kept at bay only by a young girl with psychic powers named Eleven, who is the product and escapee of a top-secret government experiment that was being conducted in a laboratory close to Hawkins in the years leading up to the show’s present. Both the program that produced Eleven and its Soviet analogue, it is eventually revealed, are responsible for incubating ruptures to the Upside Down. They are the structural supports that sanctify the show’s bestial bloodbaths, bureaucracies whose ideological contours enable and perpetuate ST’s phantasmagoric violence, its psychoanalytic perversion and (thus) its captivating plot points.
This is a picture of Netflix’s Stranger Things (hereafter ST), a television series now with four complete seasons as of July 1, when the final two episodes went live. (Television no longer “airs”). Unpacking the entirety of the show’s history is a complicated matter for two pages, so I focus on the episodes released July 1 as a relative present; though pasts necessarily seep in. ST in general, and these last two episodes in particular (which together have a running time of almost four hours), televisually details the extent to which this (our 21st century space) is a production of a political unconscious that some would call ’neoliberal’. Whatever we call the zeitgeist, it depends on technologies of global simultaneity.
The plot lines are hard to cold start; but when the curtain raises at our chosen beginning, the unit of fourteen heroes (all American, naturally) is separated into three groups in geographically distinct locations: Hawkins in Indiana, the Kamchatka peninsula in Russia, and somewhere in a desert in Nevada. The unit is, by self-assignment, collectively fighting a monster who used to be a human, Vecna, to keep him from killing a fourth teenager. If he manages to commit the homicide, it will ensure a fundamentally ruptured distinction between the Upside Down and the nostalgic world of an American nuclear family.
The Upside Down is, I think, a conception of the future projected from fragments, flashes of the past. As was realized earlier in the season, the materiality of the Upside Down is locked in a state years earlier than the Right-side Up, the world in which our protagonists primarily live. Vecna’s threat to rupture the two worlds is in service of a (rather unimaginitive) dream; a dream that he and his monsters might ravage and roam in 80s America. The expansion of his dominion is the future the Upside Down threatens, and in stellar capitalist-qua-colonizer fashion it seems (at this stage) to be only for its own sake. With each new victim, which he consumes as “everything that they are” parasitically becoming stronger himself, Vecna increments towards the vision of a tentacle-and-bat-rich wasteland spatially double to the world he inhabits now.
Vecna weaves his futurity into the present (80s Hawkins, which is naturally also a past) by finding sites where some fragment flash of it already exists. This is in the mental manifestations of teenage suicidal thoughts, material unhappinesses of domestic violence, or lonely White suburbia. Understanding it (his futurity) enough to resist its advancing inevitability requires journeys to the past, journeys which are often traveled by way of the flashback and other filmic techniques. Another way to think of the Upside Down is simply as purgatory. It is a futurity rooted and undetachable from multiple pasts which unrelentingly seep into the present, a Messianic combustion that enacts violence and makes way for more of it.
ST suggests that, in order to keep Vecna’s futurity at bay, we are currently relying on ambitious children. More specifically, on the ambitious American children who are top of the class in the national cults of reckless independence, of familial normativity (with just one unconsummated exception to prove the rule), and of freedom enforced by jingoistic heroism.
Now: it is not jingoistic heroism or heroistic jingoism that keeps the world’s impending collapse at bay. Nor is it the profits of technological solutionism, whether they are cashed as a psychic superhero girl, as a sentient AI, or as a global carbon sink. Nor is it the serendipitous simultaneity of jingoistic heroism, technological solution, and one or more other Liberal hopes joining forces in conspiratorial reveal, as it does in small town America in the penultimate progression of the final episode of season four. The final scene depicts an environmental line that divides two worlds that are both the Right-side Up; one which houses happy memories, and the other which rains ash, storms and earthquakes. I cannot say what it is, exactly, to progress, but let me say this: human life is not held together cinematically with the charm of second-rate acting from child stars who have grown out of their adorability. We will need a revolution of a different kind.
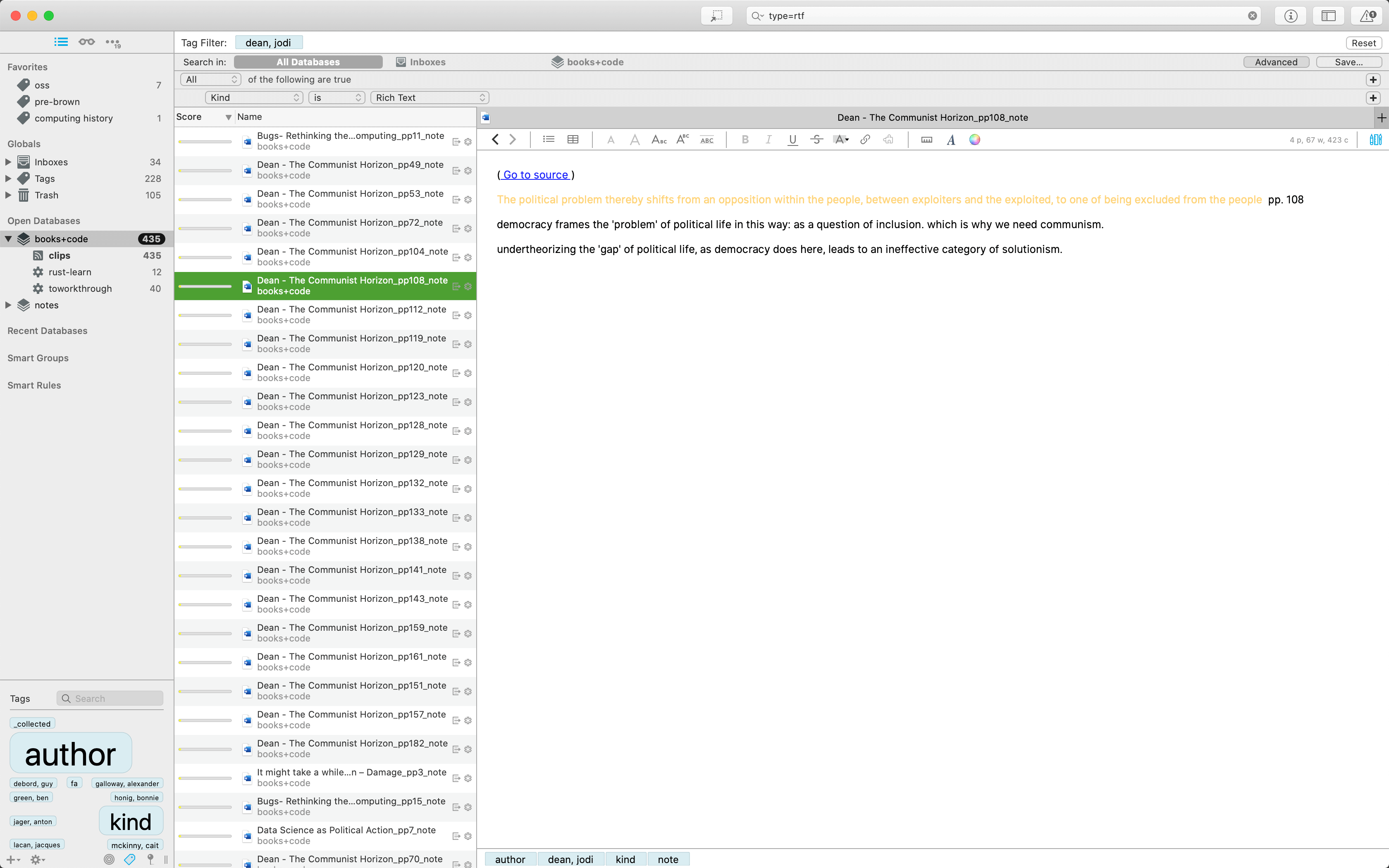
Annotations in DT have long been a bit of a brain tangle for me. My spec for annotations (since I didn't go into this in part I) is as follows:
There should be no constraints on how many annotations you can take from a document. You could take none, one or two, or ten thousand.
An annotation should have an inlined quote (whatever text is highlighted when you create the annotation), and should have a one-click reference back to the specific page of the source document from which it's drawn (if it is a PDF- for webarchives and weblocs there is no notion of pages, so a generic reference to the document suffices).
Annotations need to be their own entities in the archive. This has several implications. One of these is that an annotation is not solely or specifically bound to its source document. Annotations can be included in projects without necessarily including the source document itself. Another is that annotations can have their own tags which need not be the same as their source document's.
Annotations should be recognizably distinct from other documents. This is perhaps a personal preference, but I think that it makes sense given that an annotation is part source text, part text that I myself have written (an associated note). In this sense annotations are closer to files in my PKB (explained in brief at the top of this post) than any other content in my archive. They are part source material, part my own creation.
Creating annotations should be possible _from anywhere_: not just within DEVONthink.
Though it leaves a bit to be desired in my workflow, it does make sense to me why DT does not include support for annotations natively. DT wants to be as general-purpose a file manager as possible, and to not force your hand when it comes to file formats or workflows. The conception of an annotation that I have above is something fairly specific to an academic or otherwise citational workflow, and might not be necessary for many folks' file management philosophies. For many, DT is a starting point: it opens up onto other applications. Having some sort of DT-specific file type for annotations would run against this.
Annotations as RTFs (my old approach)
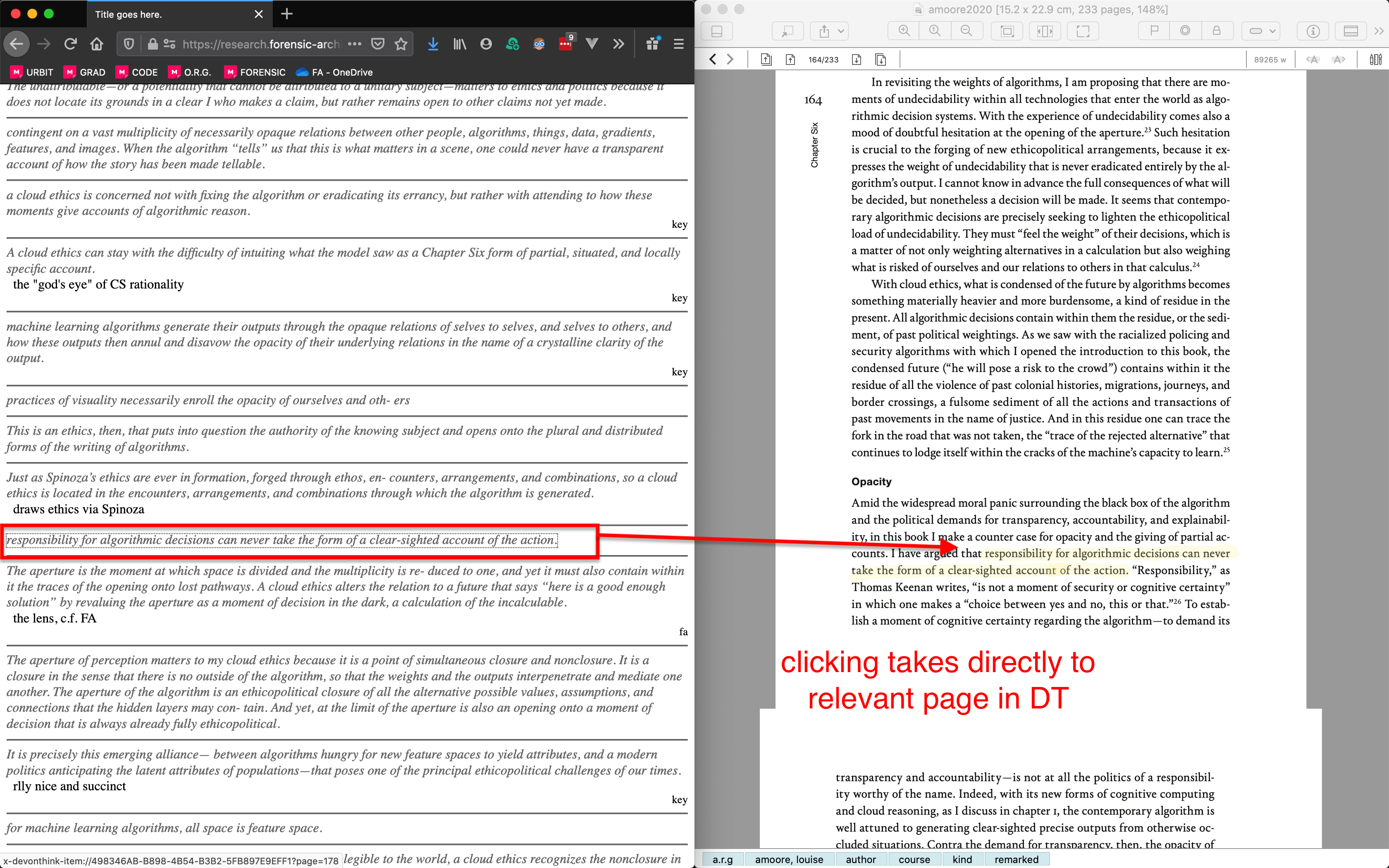
Though it doesn't support annotations out of the box, many have tried to create an annotation workflow in DT. See here and here for some examples. A common way to manufacture annotations is to create a shortcut that creates a new text file from a template, which includes a link back to the source document via DT's URL schema (which allows you to open up specific documents, at specfic page numbers, from anywhere on your Mac).
This works okay, and I used a similar workflow for a long time: Cmd-Option-; to automatically create a new RTF with the highlighted text in a different colour, with a hyperlink at the top that can take me back to the quotes source. (If you're interested to try this approach, my script is available here) Any other notes I wanted to write about the quote just went directly in the RTF document beneath. This approach satisfies at roughly three and arguably four of the conditions outlined above, with the arguable exception being number four: RTF documents are not particularly distinct from other documents, especially if you happen to have word documents and other rich text as source documents in your archive. You can get part of the way there by using a naming schema for RTF annotations, but it was still a bit messy by my measure.
Most importantly, creating annotations from outside DEVONthink gets messy very quickly, meaning that this approach falls flat on condition five. In theory, you can write scripts to generate RTFs on other devices, and then you could work out some syncing mechanism to carry those annotations into your main DT workstation at some point via Dropbox or otherwise: but it's not ideal. Moreover, RTF isn't the most straightfoward format to generate. (Although admittedly you could replace RTFs with Markdown or something similar; it just wouldn't look as nice inside DT.)
Annotations as RSS (my current approach)
A month or so ago, I came across Francis Tseng's wonderful writeup regarding his research tooling. One of the components of his workflow is a super simple HTTP server called hili, which accepts 'clips' at a POST endpoint, and stores them as simple JSON. Clips contain whatever the source quote and images, a reference to the URL where the clip happened, and optional tags that can be used further on to help categorise the clip.
I really liked this idea, as it detaches the idea of taking notes from any application in particular and makes it universally available wherever there's an Internet connection (and the ability to send a simple POST request). I modified hili by adding the ability to take a note associated with each clip, and added scripts for DEVONthink and iOS in addition to Francis' original extension for Firefox.
For a while I clipped away while reading on my various devices, building up a database of clips from both webpages and DT documents. Thanks to DT's URL schema, I can treat DT URLs in the same way that I do HTTP ones: as hyperlinks that can open up the right document in DT from wherever else (i.e. directly from the browser in which the clips are shown. Note that this won't work using my clips, as the DT URLs are local to my computer).
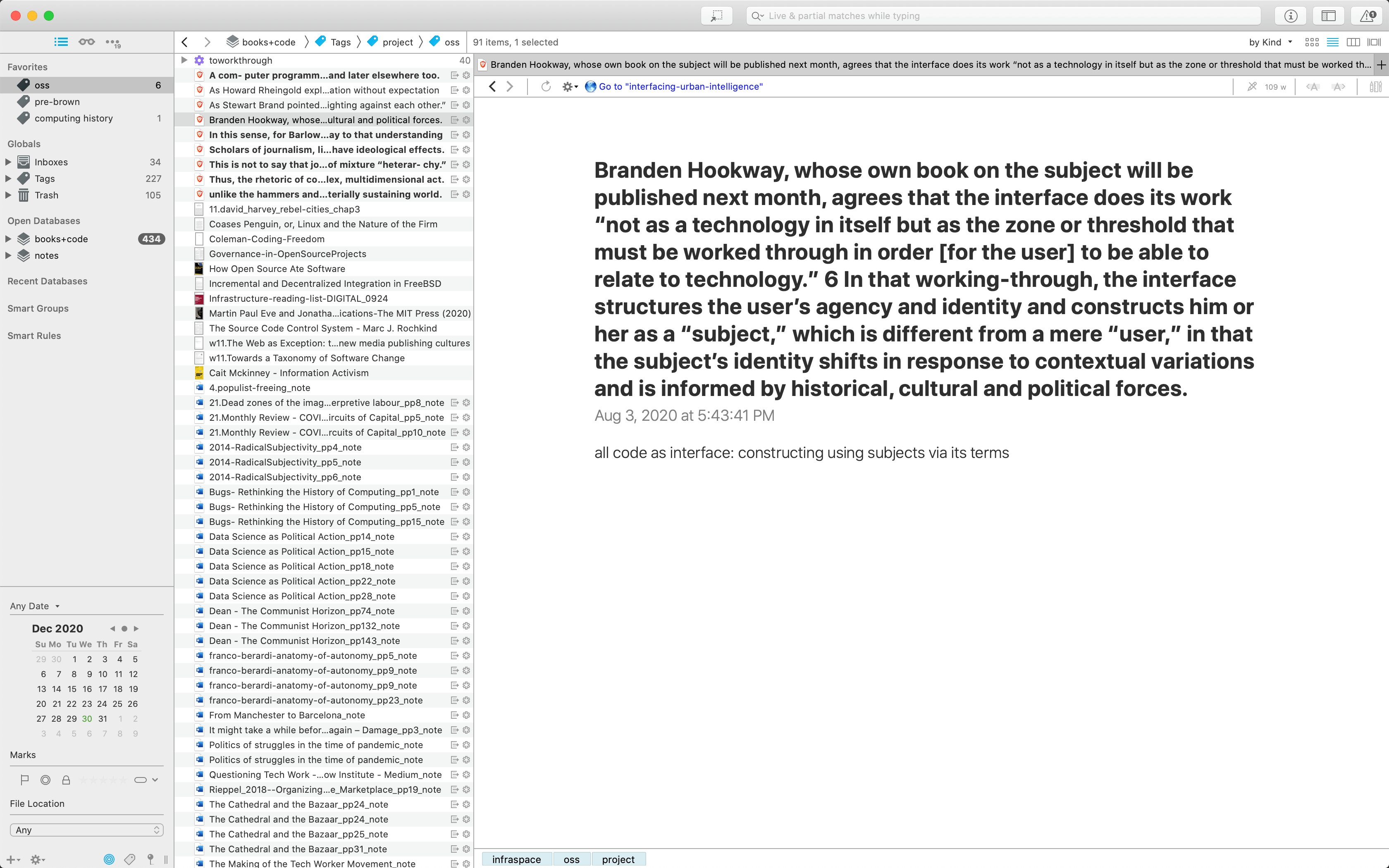
The HTML view of clips pictured above is handy, and is nice to confirm that cilps are coming in, or to quickly search for a clip from wherever: I just have to open up a browser from any device to my hili URL and I have them all. I developed a basic way to filter clips by tag- but quickly realised that I would have to build a full frontend interface with full text search to really get the most out of my clips.
Even then, the clips in hili would sit separately from everything else in DT, which is less than ideal. I use the same tag structure with clips as I do with DT documents-- some are associated with projects, others by type (see part II for more detail on this structure). Ideally, I would like to filter for a project tag in DT, and see both all DT documents associated with that project, and also all of the hili clips I've tagged as relevant to that project. As per specification #5, I do want annotations to be somewhat separate from source documents: but if they're only available in an entirely different interface, it means that I would basically have to do every search twice; once in DT for documents, and then again in the hili webview for annotations.
While looking through one of Francis' other projects recently, I realised that I could have the best of both worlds using a tried-and-true technology (and perhaps my favourite data format for its collection of curiously coexisting qualities: relative obscurity, ubiquitousness, and decided simplicity): RSS.
RSS is usually used to 'syndicate' news feeds from various sites, making all the content available all from single reader such as Feedly or Newsboat. The format it uses for news items, however, is also almost perfect to represent a document annotation. It contains some header text, a description, a source URL, and a set of tags that can be used to categorise the item.
Moreover, DT supports RSS feeds in such a way that item tags are automatically attributed as DT tags. This means that if I tag a clip as 'infraspace' when reading, when that clip comes into DT as an RSS item, it'll automatically be associated with all of the other content in that project. Making my clips available as an RSS feed gives the best of all worlds: I can clip from anywhere, view clips in HTML at a glance (if I'm not at my Mac), but also keep all clips as integrated and distinct items within my archive.
It also means I get the full power of DT search for my clips, so I don't need to think about developing a new UI to group all those related to a particular document, say, or all those that have a particular tag, or all those that I clipped during a particular time period. They show up beautifully in project workspaces, with a distinct type (HTML text) that doesn't overlap with other documents in my archive (as RTF annotations sometimes did with Word docs), and one click away from their source documents like the HTML view.
More to come…
Francis and I are working on integrating our hilis, which might lead to it becoming a more stable tool for folks not familiar with Python and HTTP requests at some point: but if you're not afraid of Python and want to try it, please do! I'd be very happy to hear about and help anyone who's interested to mess around with it (email me or open an issue on Github if you run into trouble).
Following on from Part I, here I'll unpack how I archive in practice using DEVONthink (DT) as a driver. As I noted in part I, DT is a Mac-only application, and so in order to replicate my setup, you unfortunately need to have an Apple device. I'm actively looking for linux software that can simulate or replicate DT's functionality, as my primary workstation is Artix on a modified LARBS, but I currently know of nothing that compares. In fact, it is pretty much solely DT's capabilities as archiving software that ties me to still using a Mac for some kinds of work.
Alongside documents in DT, I also keep a personal database of notes in plain markdown, which I view and edit in a range of ways (Obsidian, vim or emacs in desktop environments, and iWriter on iPad). I call this database my "PKB", which is a shorthand for "personal knowledge base" I picked up somewhere online. My PKB loosely follows Nick Milo's LYT method for note-taking, and contains notes that range from handy bash commands, to lecture notes, to article drafts.
My Obsidian graph. Edges between notes represent lateral links.
I'll unpack my PKB in more detail in a future post. I mention it here because it structures the way that I use DT. DT is where I read and seed ideas; my PKB is where I grow them as research. In other words, my DT archive exists largely to service the development of my PKB.
An associative archive in DT (or another application) can supplement any research output process, whether it takes the form of a PKB like mine, whether it's a Roam Research database, folders in Evernote, or whether it's just a good old blank Word document.
My DT setup involves several customisations. Some of these are straightforward, and I'll do my best to detail those here in such a way that they can be easily reproduced on any DT installation. Others involve custom Python scripts and external services like Dropbox. If you're interested in the detail of these, or have any questions or comments in general, please do feel free to email me. If you've taken the time to read this, I'd love to hear from you! :)
DEVONthink in a nutshell
DT is ultimately a file manager, comparable to Finder in Mac, File Manager in Windows, or Nautilus or PCManFM in Linux. To get started, you create a database, in which you can then store files of various kinds. With DT, you can then effectively browse and modify the contents of your databases.
DT is superior to a traditional file manager in a range of ways. Firstly, it is conceived as a way both to find files, and to view them. The left side of the screenshot above looks much like Finder; the right side looks like Preview, or some other PDF viewer. DT's PDF viewing and editing is slim and straightforward, and much more effective than Finder's 'preview' functionality for basic viewing. I've found it capable of everything I want to do regularly with PDFs, including highlighting, adding notes, and jumping to page numbers. If there's ever anything lacking, you can double-click and open the document in another application, just as you would in Finder.
DT doesn't only support viewing and editing PDFs; it provides similar capabilities for most file types that you can imagine: images, CSVs, markdown, and many more. Crucially for my archiving, it supports both .webloc files (which are basically bookmarks for webpages) and webarchives (offline webpages). This support means that I can view webpages alongside PDFs in the same view, treating them as analagous, rather than having to employ a different storage system (such as browser bookmarks) and set of viewing applications for each distinct file type.
DT also offers fluid conversion between document formats. I can right-click to save a .webloc as a webarchive, or to convert a webpage to a PDF. (Webarchives in particular are a revelatory format: because it's HTML saved locally, you can edit it and add in your own highlights, hyperlinks that point locally to other DT documents, and styles as you might with a PDF document.) DT offers a huge range of useful operations: making a new PDF by excising a range of pages from a larger PDF, wordcounts over documents of various kinds, and many others.
Like Finder, you can toggle through a range of different views on the list of files on the left-hand side. You can even modify its orientation with respect to the document viewing panel (which can sit on the right as pictured above, below the file list, or be hidden).
Organisational concepts in DT
There are two primary organisational concepts in DT: groups and tags. Groups are essentially folders: nodes that exist as the parent to a collection of children documents. Tags are more flexible, and less hierarchical. They are distinct tokens that can be associated with any document, and subsequently used as composable filters to view associated documents.
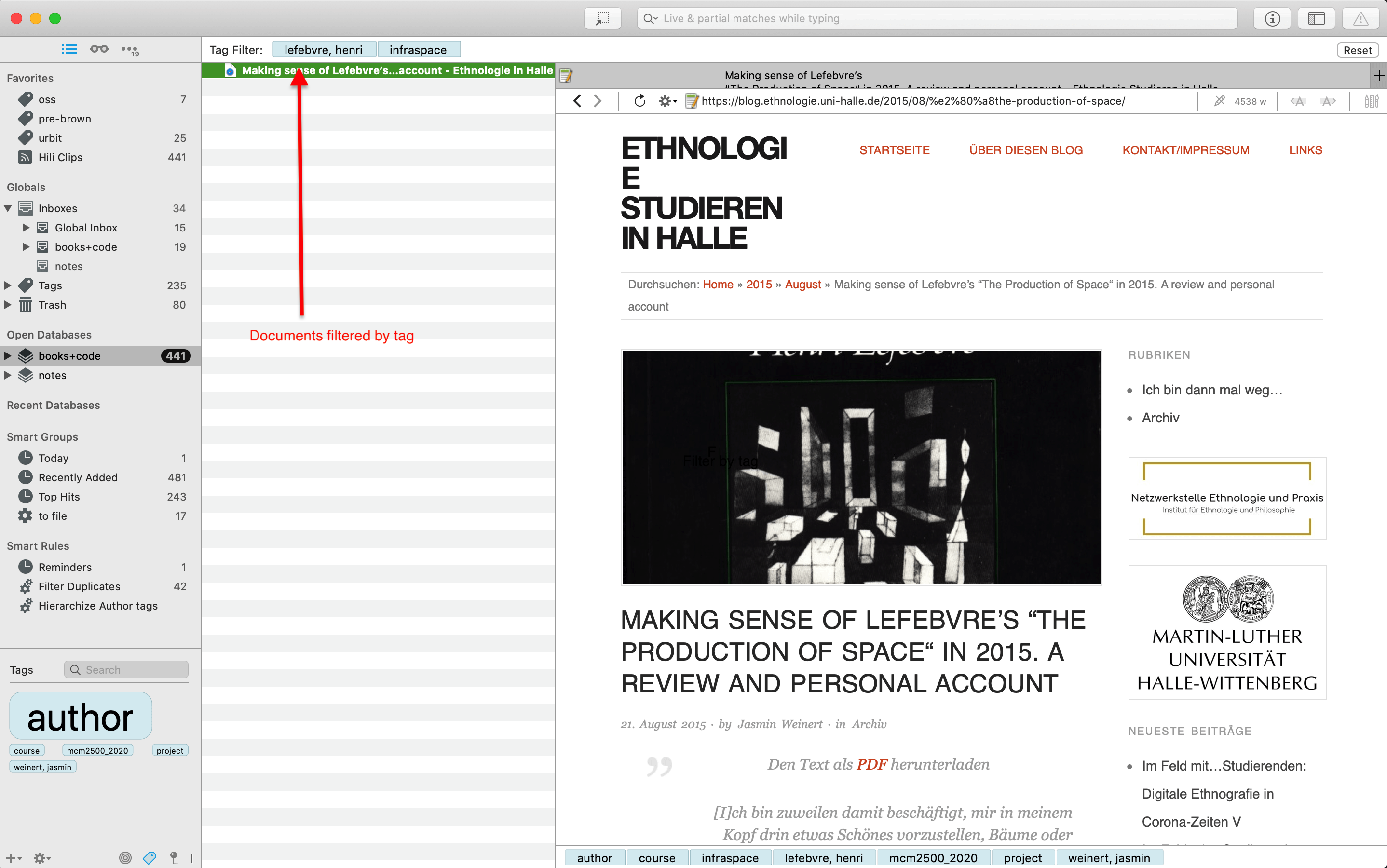
If you've read part I, you won't be surprised to hear that I almost never use groups, and use tags extensively. DT's tagging system is what makes it so effective as an engine for associative archiving. You can filter for documents associated with one or more tags in any database:
In addition to basic filters, i.e. for documents that are associated with a particular tag, you can compose arbitrarily sophisticated filters over a database to retrieve matching documents. These filters can make use of document tags; but also all of their other metadata, such as date created, date modified, document kind, to name just a few:
In addition to this metadata query language, DT provides impressively effective full text search. This operates over documents of all kinds: PDFs and webarchives alike, any document that has text that DT's indexing engine can pick up on. (Certain versions of DT also provide support for OCR-ing PDFs that don't explicitly contain textual data.) Combining this with tags, I can query for documents in DT using arbitrarily complex directives, such as "Give me all PDF documents authored by Jodi Dean that contain the word 'manifesto' that have more than 10000 words". Results are ranked using a scoring algorithm, so that must relevant results come to this top. Searches can be done either succinctly via DT's query language in the search bar, or visually using the provided GUI.
Associative archiving in DEVONthink
The three primitives of associative archiving as I outlined them in part I are: projects, associative tagging and an inbox. Here's how I implement each of these using DT.
Projects
For each new project in DT, I simply add a new tag, and start attributing it to documents that exist in that project. Seeing all the documents in a project is then as easy as filtering for a tag.
In addition to working as a filter, tags exist as distinct entities in DT. This means that they can be searched for, added in groups, and so on. One shelf that DT offers in its global sidebar (on the leftmost of the screen below) is a list of 'Favorites', to which you can add any kind of entity. By adding a project tag such as 'computing history' to my Favorites, I create a distinct workspace for that project, which will dynamically show me all documents within that project. From this workspace, I can then further search and filter over tags, metadata, or contents.
Associative tagging
I have a few special categories of tags in order to keep my archive clear and usable. The architecture of my archive's tags is an eternal project: I'm endlessly creating, renaming and consolidating tags together in order to make them more effective as filters and search concepts for my research. This dynamic change is possible in DT, because tags are more flexible than folders: deleting or renaming one won't remove associated documents or break other connections, it will just remove that tag.
Project tags - correspond to a project as described in the section above.
Author tags - a tag for the author of a document. This is a bit more robust than relying on DT inferring the appropriate metadata, I've found, as PDFs and webpages sometimes don't contain the information appropriately for DT to pick up. Author tags exist in my archive in the format "lastname, firstname", e.g. "dean, jodi". Any tag that includes a comma I treat as an author tag.
Kind tags - a tag that marks some quality of a document that I want to track(i.e. it's 'kind'). This ranges from my own interpretations of the document ('interesting', 'difficult'), to its genre ('literature', 'journalism'), to its medium ('podcast', 'video'), to some parenthetical note or impending course of action ('toread', 'reading', 'unread').
Journal tags - the journal or publication source of documents ('duke university press', 'jacobin', 'verso'). As in the case of author tags, this is more resilient than relying on metadata inference.
Field tags - disciplinary or otherwise structuring fields in which documents exist. I mainly use these as ways of capturing pockets of technical literature in computer science, i.e. 'databases', 'decentralised', 'p2p'.
Course tags - tags for seminars that I take or teach. All of the readings are tagged with the course tag ('MCM 2500 2020'). I used to use tags for particular weeks of content as well, but this gets complicated if certain documents are read in multiple courses (as they may be read in week 1 of one course, and week 4 of another). Instead I now rely on the course's syllabus (which can be found using the type tag 'syllabus') to preserve the course's progression.
The basic guiding principle here is that my tag architecture should reflect the way that I conceptually order documents, so that retrieval from the archive is as simple as composing a few tag/concepts together. Search is not the only application though; wandering through my tag architecture can also lead to serendipitous discovery of links between different kinds of content. Keeping the archive 'flat' by default encourages this latter kind of discovery, and keeps categorisation from ossifying and stymieing creativity rather than supporting and structuring it.
The inbox
The final component of the associative archive is an inbox for incoming documents, which are either to be read or simply shelved for later. DT comes natively with the idea of a 'Global Inbox' that represents a holding shelf for documents before they go into whichever database.
It is easy to drag-and-drop files such as PDFs if they're local into the inbox, and DT also provides extensions for Safari, Chrome and Firefox to easily 'clip' webpages into the inbox.
I use DT's inbox as my primary way of keeping track of links and documents to read. Because it exists separately from the rest of my database, I can sync it with the mobile version of DT, DEVONthink To Go, without having to worry about taking up all the space on my tablet with all my PDF documents (which can be stored on the Cloud and synced on demand if you prefer). My DT inbox becomes a 'Read Later' space for everything incoming from either the web or that folks have sent me as PDF.
If I didn't have an e-reader, I would probably read PDFs on my ipad via DT To Go as well: but because I start at a glowing blue screen so much in any case, I make a point of reading everything I can on my e-ink Remarkable tablet. PDFs basically sit in my DT inbox for as long as I'm reading them, as a kind of reminder that I need to, and then once I have finished with them on Remarkable, I export them and replace the placeholder documents in DT with the annotated versions.
To be continued…
I only intended to have two parts, but in Part III I'll explain how I manage annotations on documents in DT. As I'll explain in more depth there, this is slightly beyond the scope of DT as an 'archive' per se, as it gets into how I use my DT archive to write and produce my own research.
There might also be a part IV, in which I'll go into more detail about my PKB and writing process. Both my annotation system and my PKB are more freshly minted than my DT archive, and as such they're still developing and are subject to change and improvement. They work pretty well for me at the moment, though, so I'll write up their processes in the hope they're useful/interesting to some.
I've been using DEVONthink (DT) idly for almost two years now. For those who aren't familiar with the application, you can basically think of it as an extra layer on top of the Mac operating system for working with documents (PDF, images, RTF, etc) more effectively. It has inbuilt PDF viewing and annotation, facilities for syncing documents between computers and tablets (iOS only), powerful search capacities, lateral tagging to associate documents with each other, and-- most importantly-- a scripting API to create custom workflows.
I've recently been ironing my reading, writing, and archiving workflow. It's designed primarily with seminars, essays, and book-length projects in the humanities in mind-- but I've tried to make it general and flexible enough to work with other contexts, such as scientific reading, as well.
This is a two-part post. Here in part I, I'll present a specification of how I want to read, write, and archive in abstract terms. In Part II, I'll detail the way that I've configured and customized DT to implement that spec in practice. I hope this can be helpful/instructive for some folks out there who similarly work with networks of citations in reading and writing projects, or who keep a personal archive of PDFs.
A note for readers looking to use the configurations and scripts in Part II: DT is not free, and it's Mac-only. (I'm looking into virtualising it so that I can run it in Linux, but that project is yet to begin.) There is a generous 150-hour free trial, but after that you'll need to make one-off payment of $99 USD for the standard version on desktop. I'm more than willing to pay for good software like DT, and you should be too. Developing and maintaining software takes time and effort. I'm very grateful to the folks at DEVONthink keeping up with the community, and keeping the software feature-rich and flexible.
Projects
My archival philosophy is built on the principle of projects. At any given time, I have a number of projects underway. A project might be an idea for an essay, an essay I'm actively writing, a coding project, a reading group, a talk I'm preparing- essentially any undertaking that collects together relevant links, quotes, notes, texts, and other files.
These projects much more actively organise my archive than perhaps more familiar taxonomic concepts such as author or date. When I'm reading and writing, I store relevant information in my archive according to where it's going in my work-- in projects-- rather than where it's coming from. Say I'm reading a book, and a particular paragraph sticks out at me as a relevant reference for an essay I'm writing: I want to save that quote (and perhaps some relevant additional thoughts regarding why the quote is relevant) in the essay as a project. Provided I can get back to the correct page in the source document from what I save, I don't need to file the entire book in the project; just the relevant quotes and my additional annotations.
When I go to work on a project, I can bring up its file of quotations, annotations, and my own personal notes. Quotations are hyperlinked to their source text, so that I can go to its origin to cite or further explore, but my main project workspace is a readily-accessible collection of relevant quotes and notes.
A single note/quote could be relevant to arbitrarily many projects. Notes can exist in a project without a source document, thoughts that occur to me in the course of conversations and everyday life. The source documents might be either a PDF or a webpages. (Hardcopy books can't be hyperlinked, so quotes for these are just traditionally referenced by page number).
Project workspaces
When I open up project workspace, I want to be able to easily and immediately view all of the relevant quotes and notes. I want to be able to dynamically search through the workspace in a number of ways: for particular text, filtering to only notes from a particular book, only notes from a particular author, only notes written after a certain date, etc. In other words, the project workspace search is where I need the more traditional taxonomic notions to organise my files. I don't want to have to click through nested file structures to get to relevant notes, but instead be able to flexibly filter and compose notes.
The notes in projects should contain everything I need to use and expand the thought in a project. The project workspace is where I sift through these thoughts, putting them to use in the project, whether that be towards code, writing, conversation, or whatever else.
An associative archive
Projects are the main way to interface the archive for writing. However, I also want to be able to search through the archive as a whole, without limiting search results to the confines of a project. This search should, like the search in project workspaces, be similarly flexible and support search by author, by date added, etc.
Crucially, I also want to be able to add durable filters to the archive's search space. For example, I might want to be able to see all notes and documents from a particular seminar, all those published by University of California Press, or all those that come recommended by a particular person. A document or note can have an arbitrary number of these tags, so that it can be infinitely associated with other items in relevant groupings.
This notion of flexible and associative tagging essentially replaces the need for folders in the archive. Folders seem to tend towards nested hierarchical structures of organisation. I try to keep as few hierarchical layers as possible in my tagging system. This keeps me diligent regarding the tags I add to my archive, encouraging fewer of them and ensuring that the ones I do add are expressive and memorable.
The inbox
The only extra capacity this system needs is a clean, clear workflow for adding new documents to the archive, reading them, and then marking them as 'done'. I work through documents like I work through email. They enter into an inbox, and I read them there, creating new quotes and notes in different projects as I read. When I'm done, I flick them into the archive. Documents either come into my inbox fresh from somewhere else (the web or a hard drive). Or, if I'm returning to a document to read a different chapter, or to read one again, it might come back into my inbox from the archive. In other words, my inbox consists of all the documents I'm actively reading. If I'm adding a bunch of documents to my archive from elsewhere and not immediately planning to read them, they only hang out in my inbox for long enough to be tagged with any relevant filters, and are then filed away.
The idea that a document can be either a PDF or a webpage is crucial to how this inbox works for me. For a long time I kept webpages to read in browser bookmarks, and PDFs elsewhere, which inevitably ended up in never actually reading bookmarked folders. Having a unified inbox for all my documents means that I have to work systematically through them to keep a clean inbox, just like an email inbox.
Another important aspect my inbox is how it works with documents I read elsewhere. I read almost all my PDFs, EPUBs, and MOBIs on my Remarkable, where I underline things and write in the margins. When I've finished with a document on my Remarkable, I bring it into my archive inbox, and browse quickly back through the marginalia. This practice of 'second-reading' my own notes on a text helps to solidify what I took from it, and gives me the opportunity to spin off relevant quotations and marginalia as notes to projects. I have a system for reading with my computer open as well, annotating and typing notes as I go through it, but I largely prefer reading elsewhere (outside, in the sun!) and then second-reading in my archive's inbox, before filing it away. Similarly, if I take notes in notebooks on my remarkable, I second-read them in my archive before filing.
In Part II, I'll explain how I have implemented the archive explained here in practice with DEVONthink.
A synopsis of Trinh T. Min-ha's argument in her 1990 essay, "Documentary Is/Not a Name". You can find the essay here.
If we characterize ‘culture’ as the gestures (rhetorical, occupational, infrastructural) that Man invents to make an environment wholly livable, its is clear that such gestures will be subject to Man’s historical particularity at any given moment. One normative gesture in the plans of our present cultural architecture is Science. Science’s pragmatism substitutes the need and often desire for other religiosities, as its explanatory thrust is more epistemologically compelling than its misbegotten alternatives: myths, legends, and other fanciful fictions.
We no longer have need of deities to euphemise a complex set of processes. We know how any why the sun rises. We know how and why the monsoons come, I think. In secular society, gods have no currency: science is where people can get funding. Maui, the trickster demigod who fished New Zealand out of the ocean with a magic hook, which his brothers then greedily ate to form the many valleys, mountains, lakes, and rocky coastlines of the North Island, is now only a company that sells and rents camper vans.
There are no longer conflicts amongst the gods. A storm is not Poseidon’s anger, nor is winter Persephone’s absence. They are processual protuberances whose oracle is data; and preferably big data. Life is a laboratory of uncontrolled experiments—not of the gods’ temperaments, but of particles, atoms, and bits.
Yet science, like many other soothsayers, has not yet proven to explain everything. It continues an impressive epistemological career, from its zealous preamble as mechanical philosophy in the 17th century (see Steven Shapin) to its trusted management and regulation of the Earth’s sensitivities in the 21st. At times it is egotistical, forecasting more than it has license to understand. At these times we are tasked to note, as Thomas Hardy did for the fishes in poetic eulogy of the Titanic: “What does this vaingloriousness down here?”
Science does not have to be fashioned in opposition to nature, but in its practicalizations it often is. It can be a heady bastard, loathe to accept there are problems it cannot synthesize. Though I trust its good intention, its actions often read as susceptible to the destructive caprices of egocentrism. If it could live with roles that are not so clearly coded ‘black,’ or ‘white,’ it might come to the conclusion that the neighborhood does not need saving. Gotham is a fictional city, as is Metropolis. The dichotomy of hero and villain are never so resolutely coded in real life. Gods can be kind and they can be cruel.
A collaboration with Michelle Lord Goldman and Cecily Polonsky. Directed by Jhor van der Horst, edited by David Lopera, and featuring Natalie Plonk, Ben Diamond, Raheem Barnett, and Ysa Ayala.
Since React’s open source release in 2013, techniques inspired by functional programming have become an integral part of what many consider ‘best practice’ in front-end application development on the web. Functional programming as a concept has been around since the lambda calculus was invented to study computation in the 30s, and it became practicable through Lisp in 1958, and then further through ML in the 70s. Only now, however, is it finding its way into the mainstream. This post investigates functional techniques in contemporary ‘best practice’ front-end development by comparing an application in Elm to its equivalent in React.
Disclaimer: I think Elm is a lot more expressive and robust than the React equivalent.
What follows is a ‘translation’ of Elm’s syntax to its React equivalent, demonstrating what abstractions are shared between the programming dialects. By contextualizing the approach of each framework within the web’s history and the JS ecosystem, I argue that Elm offers a more concise and expressive syntax for than the ‘best practice’ React application, as both frameworks are intended to be used through the same architectural primitives. In addition, I also provide brief reviews of JS frameworks that employ a similar architecture (which I’ll simply refer to as the ‘Elm architecture’ from this point on), comparing them to Elm and pointing at how Elm is more concise and expressive in comparison, in the same way that it is for React.
In order to clearly compare React and Elm, I’ve made a very simple ‘books’ front-end interface that makes an HTTP request, and visualises the returned JSON data (which represents some of the books I’ve read in the last couple of months). The code for these applications, as well as instructions to run them, are available in the folders elm-books and react-books in the following repo:
When referencing code in the following post, I’ll refer to a set of line numbers and the file in which the code can be found, implying the appropriate directory through the filetype. For example, the reference [1-12 Main.elm] refers to lines 1 through 12 in file the file elm-books/src. Alternatively, [2,6-8 App.js] refers to line 2 and lines 6 through 8 in the file react-books/src. Links to the relevant code in Github will be provided as they are here.
Background: React
The composition of components in a tree is an intuitive architecture for view interfaces, and some variation of it is implemented on almost every modern application platform that supports a UI. The browser, for example, constructs its view through a tree of HTML nodes. The iPhone and Android platforms use tree-based abstractions such as Views and View Managers to handle the pixels they render on-screen. The application as a whole is usually composed as one large ‘layout’ component that nests several child components (e.g. header, body, footer), each of which in turn may nest their own child components, and so on.
In the browser's case, the tree of HTML nodes is represented as a data structure in the JS runtime. This structure is called the Document Object Model, more commonly referred to by its acronym, the DOM. The HTML view can be adjusted by modifying the DOM in the JS runtime, and these DOM updates are then transmitted to the actual HTML component tree. Modifying the HTML through the DOM is relatively computationally expensive, as the web was built on the premise of serving static documents, with JS and the DOM (i.e., the browsers utilities that allow dynamic updates) only added later. It is much less taxing on the browser to run JS that does not access or modify the DOM.
We have come to expect much more of the web than static documents in 2017. In the popular imagination, many complex websites are conceived as analogues of native application platforms such as iOS and Android, and are expected to provide the same quality of interactivity and interface. This type of interactive web page is now known as a single-page application (SPA). There is an enormous collection of JS libraries that provide developers with utilities to manage DOM updates at higher levels of abstraction, and more intuitively. The most widely used of these is jQuery, which is a flexible collection of functions that access and update DOM nodes with an arguably more intutive syntax than the base DOM API. In many cases, a library will provide both a strongly opinionated toolkit (collection of functions and classes) for managing the DOM, and also one or more practicable development strategies which promote particular abstractions for managing complexity. We may call these strategic libraries frameworks.
A successful framework insulates the developer from the DOM’s technicalities, and allows her to architect an application on higher level primitives than those that the DOM provides. For example, Angular 1.x, maybe the most popular full-bodied framework of the last 5 or 6 years, provides abstractions such as controllers and two-way data binding, along with many others, to allow the developer a Model-View-Controller (MVC) architecture for her applications. Controllers manage a certain scope of DOM nodes and their updates, and two-way data binding facilitates connecting one state of the screen to another state, for example the value of an input node to the text in an h3 tag.
There has recently been a revision in the philosophy of DOM access used by many JS frameworks in the ecosystem. In 2013, Facebook open-sourced a JS framework called React, which was being used internally at Facebook. React has since enjoyed widespread adoption as a front-end framework in the tech industry. This crusade is led by its extensive use at well-respected companies like Facebook and Airbnb.
React’s core design principle is stated on its website: “the key feature of React is the composition of components.” While frameworks like Angular 1.x were pitched as a holistic framework for the browser, where almost every conceivable part of the application--view declaration, state management, routing, dependency injection, and much more--is handled in some way by the framework, React declares itself only as a way to “build encapsulated components that manage their own state, then compose them to make complex UIs.” It does not strictly opinionated other essential aspects of the SPA, and this flexibility is one of the reasons for its popularity. As I will make clear in later sections, however, despite its interoperability with many types of development, React is designed with an a particular ‘holistic’ SPA architecture in mind.
The primary way in which React differs from frameworks like Angular 1.x is in the way that it registers and performs updates to the DOM. The SPA is constantly updating different parts of the DOM, handling side effects such as user input and asynchronously delivered data. In a typical SPA, there are thousands of nodes in the DOM tree. When we recall that the DOM is really optimised for one-time render of documents, not an application of changing frames that updates constantly, it is evidently important that a framework for the browser be economical in the way that it performs DOM updates.
As the complexity of applications on the web like Facebook increased, they discovered that “in our sufficiently large codebase, in our sufficiently large company, MVC [gets] really complicated, really quickly [for developers].” The cause of this complexity was the free, decentralised way in which updates to the DOM were being made, and the fact that the application state was distributed across the app in various different sections. As there were a lot of developers working on the codebase, it was very difficult for an individual developer understand exactly what was going on in the part of the application they were working on, because:
The section was able to be modified by other parts of the application.
It was very difficult to identify these modifications statically in the code, and even when they were happening in real time it was not always easy to trace which code or event had triggered the change.
Facebook’s solutions to these problems were:
Enforcing a single direction in which data can conceptually ‘flow’ through components for updates: down through the tree of nodes from the top.
A central location where all actions relevant to a section of the application are registered, so that all events are traceable.
However, unidirectional data flow (Facebook’s first solution) in a browser SPA is not an immediate solution. In unidirectional data flow, all updates exclusively enter from the top node of the DOM tree, and propagate down through child components. By this method, the entire application needs to re-render on every change. Given that it is computationally expensive to access the DOM via JS, this kind of complete re-render is super expensive.
Through what is essentially a very clever hack, React provides developers with the abstraction of unidirectional data and keeps updates performant through the use of a virtual DOM. The virtual DOM is a virtual representation of the actual DOM that is much less expensive to modify, as it does not actually re-render the HTML nodes. With a virtual DOM, React only has to perform its re-render virtually, which is a relatively inexpensive operation. Using a clever diffing algorithm, React then calculates the necessary changes in the real DOM, and then performs those changes without having to re-render the entire real DOM. React’s diffing algorithm is, as it notes in its documentation, “an implementation detail. React could re-render the whole app on every action; the end result would be the same.” React's performant diffing algorithm is this crucial optimization that allows React to compete in performance with frameworks that directly manipulate the DOM, while mantaining the beneficial abstraction of unidirectional data for the developer's peace of mind.
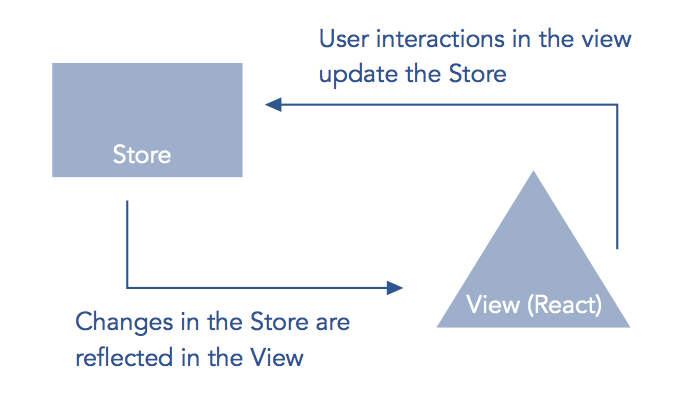
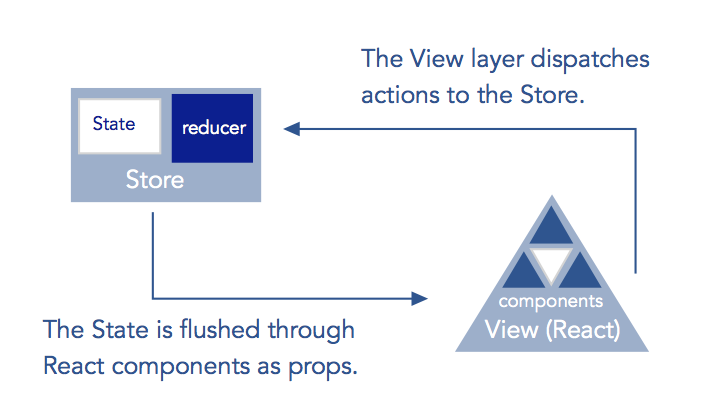
At the same time that Facebook released React, they also released Flux, an “application architecture for building user interfaces.” Flux provides state management abstractions that operate well in tandem with React components, as the library is also built around the virtues of functional programming, more specifically immutable data and unidirectional data flow. As John Reppy calls the JS event loop “a poor man’s concurrency” in his book “Concurrent ML”, the Flux architecture might be considered a poor man’s monad. Flux uses stores to represent application state, and flushes this state through a view tree hierarchy (e.g., a network of React components). Modifications to the stores may be made through a set of pre-defined actions, and the stores then emit a change event, to which views (i.e. React components) may subscribe. A library called Redux has become a popular alternative to Flux, as it essentially provided the same beneficial architecture through more powerful functional abstractions. Most notably, it reduces the burden on the developer of managing store subscriptions (a complexity that the developer has to deal with in Flux). In Redux, changes to a store trigger an automatic refresh of the view tree, and the refresh is made efficient by use of the virtual DOM in React.
The creator of Redux, Dan Abramov, was explicitly taking cues from the Elm architecture in order to reduce the conceptual complexity of Flux. I will be using Redux alongside React to express the Elm architecture, as React does not provide sufficient abstractions on its own. I will also be using some additional libraries with React and Redux to more expressively mirror the Elm architecture. Immutable.js allows the creation and management of ‘immutable’ objects in JS, which we will use in order to keep ‘immutable’ state in the Redux store. This allows for a more performant update of a large store. Redux-thunk is a library authored by Dan Abramov himself, which allows controlled dispatch of asynchronous actions to the Redux store. I will explain more about how these libraries work as they are used in the examples below.
Foreground: Elm
Though Facebook popularised the notion of unidirectional data flow in the browser through React, they by no means invented it. Nor were they necessarily the first to apply it to web’s domain through the virtual DOM. The idea of unidirectional data as an effective paradigm for state management is, in fact, an idea taken from the functional programming community. In purely functional programs, unidirectional data flow is implicit. There is no conception of ‘two-way’ data as there is in object-oriented programming; programs declaratively produce a result from a given input. In other words, purely functional programs are nothing more than simply referentially transparent functions that take an input and produce a value deterministically. Reducers, the mechanisms that manage updates in the Redux paradigm, are referentially transparent functions that take an input and produce a value deterministically.
Elm is a functional language written by Evan Czaplicki for his senior thesis at Harvard in 2012 that was designed as a more robust way of developing GUIs for the browser. Programs are written in its own syntax, and the Elm compiler then produces browser-ready HTML, CSS and JS. As Czaplicki explains in his thesis, “the core language of Elm combines a basic functional language with a small set of reactive primitives”, where “reactive primitives” come from the domain of programming known as functional reactive programming (FRP). Inspired by techniques in functional concurrent languages such as CML, Elm provides the programmer with view abstractions directly comparable with those in React (it also uses a virtual DOM), as well as an elegant and robust approach to management in synchronous updates, data validation, and asynchronous requests. Elm has been actively maintained and developed by Czaplicki since 2012, initially at Prezi from 2013, and now at NoRedInk. Both of these companies actively use Elm in production.
Component Tree
As I have noted, both React and Elm make use of a virtual DOM in order to allow the conceptual re-render of the entire application at each change, while remaining performant in the update context of the DOM. One way in which both frameworks do this is by avoiding the re-computation of pure functions with unchanged inputs. Elm’s concurrent runtime system uses memoization to do exactly thiss. React’s ‘reconciliation’ algorithm—the algorithm React uses to diff the virtual DOM with the DOM—employs a similar technique. This is possible because the functions are deterministic: given an input, they always produce the same output. Though the virtual DOM/DOM diff is conceptually the same in both frameworks, Czaplicki demonstrates Elm’s superior performance and ease of optimisation in the elm-lang blog post, “Blazing Fast Html Round Two.”
In terms of their use, ‘components’ in Elm and React are very similar. It is worth nothing that React has three types of components: legacy components, ES6 components, and stateless functional components. The last of these demonstrate the way in which React components can be considered simply as functions [6-17 components / Desk.js]. The most conspicuous difference between Elm and React components is the different syntaxes of HTML markup. React, by convention, uses JSX, a syntactic sugar that allows components to read like HTML elements. Elm, on the other hand, uses a collection of functions, isomorphically named to suit the full set of HTML tags available. Each of these functions takes in two lists as arguments; the first is a list of attributes to be applied to the node, and the second is a list of its nested children. These functions are provided by the elm-lang / html library that ships with Elm. This library also provides similar functions for the relevant attributes that can be applied to each HTML DOM node, such as 'class'. Both provide a functional map utility for lists of components [30,62 Main.elm][22 components/Desk.js], though React requires an added key attribute that is unique from other keys in the containing list, as a marker for its reconciliation algorithm.
Perhaps the most notable difference in component specification is the way in which view data is validated. React allows the optional specification of propTypes [14-16, 25-27 components/Shelf.js], which will be performed as runtime checks on data that is passed into the components, and which will throw a non-blocking error in the console if the checks fail.
Let me quickly digress to talk about data validation in JS generally; responsible manipulation of data in vanilla JS is largely up to the developer. There are various JS utilities that address this concern in JS, such as Flow and TypeScript. Flow is an optional static type checker that can be inserted incrementally into a codebase, and TypeScript is a Java-like superset of JS that is strongly typed. However, it is difficult to use either of this tools fluidly with Immutable.js objects, as both are designed to type check regular JS types, rather than Immutable’s transformed ones. Certain Immutable types, such as Records, provide partial type checking, in that Records can restrict fields to a certain shape. However they do not enforce strict types for the values contained within the shape.
In order to synthesise complete type checking in React, I am using a combination of Immutable’s shape enforcement, React’s runtime propType checking, and Flow’s static type checking for functions. When data is in the Redux store, it is validated through Immutable’s incomplete type assertions. When it reaches React, it is converted to JS (a relatively expensive operation, it is important to note, especially for large stores), and then validated in React components through PropTypes, and in functions through Flow. Note also that type definitions need to be repeated across Flow and React’s PropTypes API, which violates the ‘Do not Repeat Yourself’ principle of best practice development. If this sounds complicated, it is because it is--type validation is no simply feat in React.
Elm, on the other hand, validates data entirely through its type system. As a strongly typed language, Elm will complain at compile time if the wrong arguments are passed to a function, or if data is used irresponsibly in components or elsewhere. Note that the type alias Book is used in function signatures [29,42,62 Components/Pure.elm]. Type aliases allow the programmer to define their own custom records for elegant function types such as, shelfDisplay : Book -> Html msg. This solution is noticeably both more robust and more elegant than the partial runtime type-checking I have synthesised in React.
Synchronous Updates
In both Elm and Redux, synchronous updates in the view occur reactively. Data expressing the application state is kept in an immutable structure separate from the view tree. Each time the structure is reproduced, the view tree re-renders through a virtual DOM diff. In Elm the structure is called the model, and in Redux it is called the store.
Elm’s update function works by restructuring a Msg that possibly contains data, and produces a new model by addressing the previous model from this Msg [37-43 Main.elm]. Redux sends actions to the store, which are generated by action creator functions [21-25, 27-31 reducers.js]. A delivered action reproduces the store’s structure through a reducer function [33 reducers.js], which combines the action and its associated data and with the previous state, generating a new structure. Note that in Redux’s reducer, immutable data is not enforced by default, only strongly recommended, though I enforce it by only storing data in the store the Immutable library [38,39 reducers.js] . I have chosen to use regular JS objects outside the store, for the reason explained above of using Flow to statically type check function arguments.
Async
Elm’s update function also returns an optional cmd[34-52 Main.elm] . A cmd allows Elm to perform side effects in its otherwise purely functional environment. Side effects include generating random numbers, and making server requests. When creating the model through the init function [15 Main.elm] , Elm allows an initial cmd to be executed [22 Main.elm] . Cmds can then send Msgs to the update function after completing a side effect, for example a NewShelf msg after making an HTTPS request. The cmd is not executed when it is created [66-68, Main.elm], it is only executed when it is passed through the update function [34 Main.elm].
Redux-thunk enriches Redux with an analogue of Elm’s cmds, which it calls ‘thunks’. Thunks are action creators that return a curried function (rather than a JS object), which is then applied at the threshold of the store by middleware [11 index.js]. The middleware passes the function a dispatch function, so that the thunk can send its own actions to the store, and a getState function, which returns the store’s state at a given time.
Validating JSON
Because Elm is strongly typed, values that arrive in JSON cannot be used directly. Elm provides a validation library called Json.Decode, and Czaplicki’s current company, NoRedInk, provides syntactic sugar in a library called elm-decode-pipeline. Though this explicit decoding may seem laborious to developers who are used to using JSON directly in JS, it provides a data robustness that JS cannot achieve by itself. Many runtime errors that occur in web applications are the result of dud or mistyped data that the application has received from elsewhere, and thus data validation at its entry point makes for a generally more robust application. The Elm type system requires explicit handling of error scenarios, which results in virtually no runtime errors that are the fault of the front-end. (NoRedInk has been running Elm in production for more than a year, and are yet to find a runtime error that traces back to Elm code.)
Creating a comparable validation mechanism in JS is possible, though it is laborious to make the checking rigorous, and there is an added layer of conceptual complexity. The developer has to handle the possibility of null values, a complexity that Elm’s decode libraries abstract through the Result type. The formulation is decidedly less elegant in JS [decoder.js][Decoders.elm] . (Note: there is possibly a more robust JS data validation library of this sort out there, please let me know if you know of one!)
Extra Comments
Elm also provides reactive subscriptions to values that vary over time, which are similar to streams in functional programming. These are a very useful higher level abstraction in Elm, and make it easy to create interfaces such as Kris Jenkins’ ‘Rays’. I have not implemented subscriptions in JS, though it would be possible to do so through a library such as RxJS, or Ractive.js. This is an interesting project that I haven’t looked at in depth.
Other Libraries
React is largely responsible for popularizing a component architecture with unidirectional data flow, as Facebook’s standing as a prestigious company encouraged many developers to practice web development with the framework (myself included). There are now a range of different libraries that employ this architecture in the JS ecosystem, each of which offers a slightly different angle on the Elm architecture. In this section, I review some of the more interesting libraries in this ecosystem, briefly comparing them to Elm.
Choo
Choo is a framework that provides the Elm architecture in a syntax that much more closely resembles vanilla JS. Choo’s API is almost completely isomorphic with Elm’s. Choo notes its point of difference in its readme: “contrary to elm, choo doesn’t introduce a completely new language to build web applications.” It uses a virtual DOM to perform updates, and employs a component architecture in templated HTML strings, rather than through a custom library (Elm) or JSX (React). It does not provide JSON decoding support.
Vue
Vue provides components to create a view interface, and its own library for unidirectional data flow called Vuex. This is very similar to Redux, though it places a greater emphasis on reactivity. However, Vue does not restrict the developer to this unidirectional data architecture, and it also provides many Angular 1.x features, such as two-way data binding. It provides support for TypeScript, though there are some types that this integration cannot infer. Vue suggests using HTML templates for its view syntax, which look like normal HTML with some extra Vue attributes on certain elements. It also supports JSX. It does not provide JSON decoding support.
Angular 2
Angular 2 is a remake of Angular 1.x using components as the core abstraction. Its API is very similar to React, though it is modelled as an all-purpose framework for creating front-ends, rather than only providing the view, and is a lot bulkier. Angular 2 does not opinionate your state management, much like React. It is possible to implement an application with Elm architecture through ngrx’s ‘store’ library, which is inspired by Redux. Angular 2 enforces use of TypeScript, and as a result is strongly typed. It does provide JSON decoding support, but it is not strictly typed on all values, as Elm is.
Elm as React/Redux generator
I was interested to see if it would be possible to automatically generate a React-Redux application from Elm code, to provide a general solution for creating a React-Redux analogue from an Elm program. This was always going to be mostly an intellectual exercise, as this generator would have dubious utility. As I have shown, Elm applications are more concise, generally more expressive, and more performant than React-Redux applications. Elm enables interop with JS through a language feature called ports, which allow the developer to use external JS libraries by sending necessary values directly to the Elm runtime. Because Elm is interopable with JS, there is no argument for React on the grounds that it has access to a better ecosystem in JS (an argument that often kills web application frameworks that are not written in JS). For me, Elm is an almost categorically better conceptual toolkit for creating robust front-end applications.
An Elm generator would only be usable if your developers already knew Elm, and if that were the case there would be no reason why you wouldn’t just use Elm’s compiled output in production. The only practical way a generator might be useful would be in the context of pedagogy. As more developers are familiar with React and Redux than Elm, a systematic way of mapping between Elm and React-Redux programs might provide a valuable learning resource for developers looking to learn Elm from React-Redux (or vice-versa).
The Elm compiler and most of its associated tooling is written in Haskell, and is available publicly on Github. The compiler operates through the command line tool called elm-make, which takes an Elm file and generates browser-ready JavaScript. Although I was came to understand a lot about the elm-compiler and elm-make codebases, I found it very difficult working efficiently with Haskell’s package and build manager, cabal. Simple modifications to the codebase can take minutes to build, and as Haskell is strongly typed, I found myself running into type errors simply trying to print values and find my bearing. For these reasons, I was not able to successfully modify the compiler to produce a React-Redux application from an Elm source. However, in the following section, I offer what insights and tools I produced through my investigation of Elm’s source code.
Elm Env
In order to get the elm compiler running from source on my computer, I ran the appropriate installations in a Docker container. Docker is a containerisation platform that provides a system of containers, which can be thought of as light-weight virtual machines. Containers are built from images, which are snapshots of a container’s starting state. I have created a public Docker image for a container in which you may develop and build new versions of the Elm source code. See the following repository for details:
Though I was not able to produce a custom generator for the elm-make interface, I learned a lot about the elm-make and elm-compiler codebases, in particular the means by which it generates JS from an Elm program. I have submitted much of what I learned as a pull request to the elm-compiler-docs repository, a resource for the Elm community that aspires to document the Elm compiler, independent of its creator and maintainer. This is useful for future contributors, as wrapping one’s head around a large codebase is a considerate barrier to entry. It is also useful reference for those looking to create a compiler in Haskell, as the Elm code provides a very good example of how Haskell can be used effectively. The PR can be found at the following repo:
In addition to the above documentation, I have also created a separate repository with preliminary information on how to generate a custom ‘elm-make’ generator. The elm-compiler and elm-make codebases are wonderful resources for learning about Elm and compilers, as they provide a robust demonstration of how one language might compile to another. Further work here might involve coding generators for a range of different JS frameworks that use the Elm architecture—though I suggest this with the same disclaimer as I did the React-Redux generator; its primary use-case would most probably be as a learning resource.
When you visit a URL, you are redirected through the internet to a server somewhere in the world, and code is triggered on that server, prompted by your request. Sometimes that code makes requests elsewhere, retrieving other resources from a database or elsewhere before returning files to your browser, which we can call the client, that made the request. This is how the Facebook page that you see when you visit facebook.com is different from your friends'. Even though you could both be at the same URL; the page is customized at the server-side before it is returned to your browser through the login parameters that you sent.
In simpler sites, such as lachlankermode.com1, when there are no required exterior resources and no customization, the server simply directly returns HTML, CSS and Javascript files to your browser. Browsers have been programmed to interpret these filetypes. They know how to render in color and glory the wonderful web pages that we can browse on the internet. This was really the paradigm in which the web was originally designed; it was built as a forum for the retrieval and consequent display of HTML documents.
However, we have come to expect much more of the web in 2016. Sites ought to be dynamic, viewable and beautiful from many different shapes and sizes of device, and they should interactively update based on where I click, swipe and hover. Back in 1994, Brendan Eich created Javascript at Netscape. Javascript was conceived to run in the browser on the client side to make the experience of the web more dynamic: through Javascript, the browser could partially update and modify HTML documents in response to events, such as clicks and hovers. Event handlers in Javascript could also asynschronously request resources across the web, read and write to the user's local file system, among many other capabilities.
Javascript's relationship with the original conception web of documents is really the core of how the web works today. It enables the dynamic experience of data and documents that we expect and encounter every time we open a browser. The web is more than just an organically organized global file cabinet; it is an enormous network of theatrical data exhibitions that personally interact with each visitor, exhibitions that communicate with each other in non-trivial ways.
The web's origin and history are inscribed in its practice today. The exhibitions we call websites are built on top of original document structure of the web, and the friction between what the web was and what it has become is keenly felt by those of us who develop on its platform. Programming for browsers, which we can more technically call the Document Object Model (or the DOM), is a matter of negotiating many minute updates to an HTML document in response to a range of events, all computed against the dimension of time3.
Libraries like jQuery emerged to provide ways of managing these updates and manipulations, and they were soon followed by frameworks like AngularJS and Backbone, which offer extensive suites replete with solutions to the common and immediate complexities of developing with the DOM in Javascript. Equipped with these tools, developers were able to build softer, warmer single-page-application flesh around the web's document bones. The experience of HTML in the DOM grew into the performative and interactive showcase we know and adore day-to-day in our quotidian rituals.
But as applications like Facebook became larger and larger, and increasingly complex, developers discovered that it was very hard to keep track of everything that was being updated on each event. Developers found that in attempting to change one thing, often something that seemed simple and straightforward, they would routinely break some other part of the system. In more complex applications, it was difficult to know which events were being triggered where, or how exactly data was being fed into the DOM.
In this era of complexity, unidirectional data flow was born, pomaded by a sexy midwife, React. The basic idea of unidirectional data flow is explicitly simple: data should flow in one direction conceptually for the developer, so that it is easy to keep track of. Updates to the DOM ought to be administed one at a time, in a traceable way, and preferably from one single source of truth, so that the range of updates and insertions are transparent to the developer. Parts of the DOM should not be able to reach out to a distant cousin of the DOM and change it without telling anything else. React is a very popular library that breaks up the view layer of an application into citizens that listens for changes from some authority, and it calls these citizens components.
A React component is rendered with a set of input values which are called props. Each time the props for a component changes, the entire component re-renders. In other words, a React component is a UI expression of the data that is passed into it. When the input data changes, the function is called again with the new data. React components can call functions that make or request changes to an external store, from which they then in turn receive their props. Data flows in one direction, and can always be intercepted and explicitly monitored in the application state4.
React's conceptual simplicity is made performant through some very clever way of hacking the DOM's core architecture. Because the DOM was designed to render entire documents, it is not really very good at making incremental changes to those documents, and therefore as developers we want to limit DOM updates to those that are necessary; we don't want to overwrite parts of the DOM with nodes to refresh entire components in the DOM when only a small part of the UI has changed.
React affords developers the conceptual benefit of full component re-rendering, but also only makes necessary changes to the DOM by using a virtual DOM. When a component's props change, the virtual DOM handles the component re-render in a less computationally expensive virtual arena, and then uses a clever diffing algorithm to determine which specific updates need to be made in the real DOM. This wonderful abstraction mediates between the developer's experience of application development and the DOM's anatomical requirements.
A core contributor to React's popularity in the web development community is the canon of state management solutions that is conceived alongside React itself; architectures for the external store to which React components subscribe and from which they receive their props. The most popular of these at the moment is Redux, a library written by Dan Abramov inspired by techniques in Elm and other functional programming languages. Redux offers a very robust architecture for managing the external store in React applications.
Redux popularity skyrocketed after Dan Abramov demonstrated what was possible in the way of developer tools--explicit changelogs, hot reloading, and even time travel. Redux became the most popular Flux implementation, Facebook's suggested solution for managing state in React applications. One of the keys to Redux's popularity is its extensibility. It is an architecture for state management, not an already constructed building you have to drop into your application. Managing updates to the store from asynchronous data sources, for example, is not a prebuilt capability in Redux, it rather has several possible solutions.
React's ethos of hacking existing anatomy to ease cognitive burden for the developer is unsurprisingly popular in the developer community, as it makes programming applications easier and, more importantly, more fun. This ethos has found its way to mobile development as well, in React Native. React Native allows you to write native mobile applications for iOS and Android in Javascript using React, by running a Javascript thread alongside the native language (Objective C for iOS and Java for Android). These threads communicate with each other through a bridge, over which data and event notifications are passed. This allows React Native to leverage the perfomance of native UI views and code for computationally expensive operations, and to program less expensive application logic on the Javascript thread through React. There are potential benefits here for developer cognitive burden and experience, just as in React for the web.
React and its contingent libraries are most interesting to me not as ways to improve iteration or application stabilty in industry software development (the standard evangelizations of React), but as a robust and elegant philosophy for dealing with complexity. If there is anything I can believe in, any concept of 'productivity' that seems worth striving for, it is simplifying complexity. This is one of the reasons I like programming; programming is the practice of using abstraction to manage complex anatomies, often otherwise unassailable. This is possibly the imperative of all thought we inscribe as meaningful--science, philosophy, political science, literature, music--it all looks to 'explain': to rethink complex anatomies via 'simpler' abstractions, thought configurations that are more sympathetic with the current river of our consciousness5.
Programming languages have lots of interesting ways of abstracting time (or asynchronous operation) for the developer, and Javascript is no exception. The language's most recent specification, ES2015, includes callbacks, promises and generators, to name a few.
Note that React also provides a solution for storing and redistributing data, the state of a React component. React components can hold state and modify parts of the DOM within their own assigned territory; but the core philosophy of React wants to defer most authority to a higher truth. React component state is a capability that allows distribution of authority within reasonable constraint. It's overwrought and possibly melodramatic to defer every little update to a centralized control station.